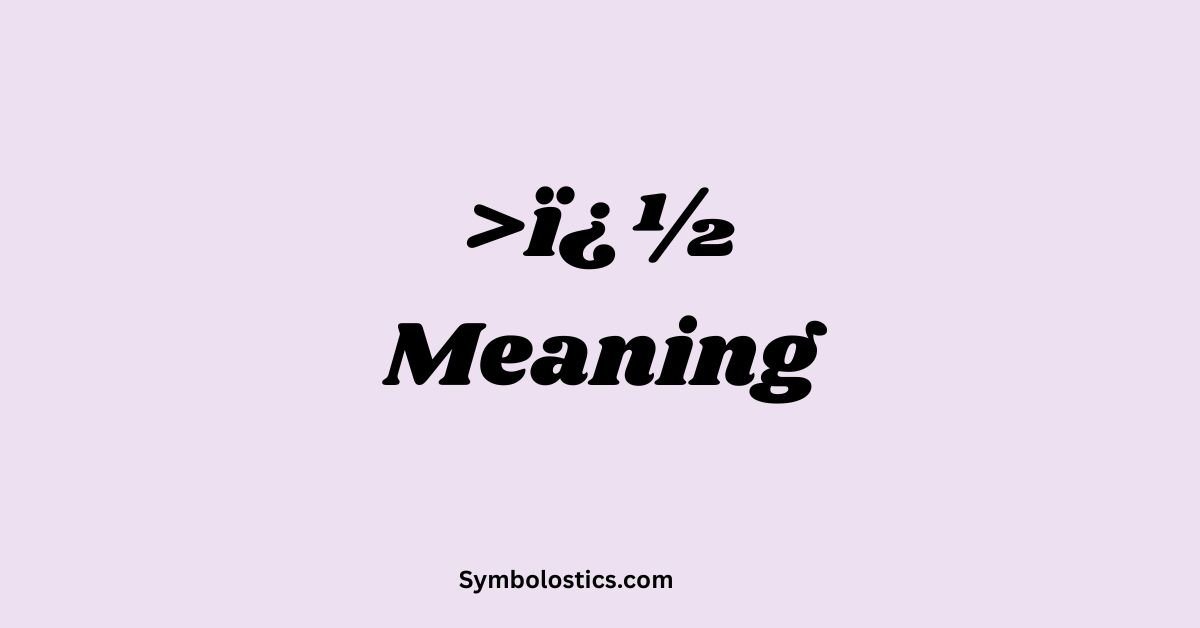
>� Meaning: Decode Issues, and Fixes (Complete Guide 2026)
Have you ever seen strange text like “ï ½”, “ï 1⁄2”, or long messy strings full of broken characters and wondered what it means?
You are not alone. This is one of the most common text encoding problems on the internet, especially when data moves between systems, languages, or programming environments like C# and Python.
In this guide, we will break down everything in a simple, human way so you can understand:
- What “ï ½” actually means
- Why this symbol appears
- How encoding and decoding issues happen
- How to fix it in Python and C#
- And how to prevent it in the future
Let’s dive in.
Ï ½ meaning
The text “ï ½” is not a real symbol with meaning.
It is a broken or misinterpreted character, usually caused by encoding issues between:
- UTF-8 (modern text encoding)
- ISO-8859-1 (Latin-1 encoding)
- Windows-1252 (older Windows encoding)
Simple meaning:
“ï ½” is usually a corrupted version of a special character like:
- “½” (half symbol)
- “–” (dash)
- or another Unicode character
So instead of having a real meaning, it is actually a display error.
Translate ï ½
If someone asks to “translate ï ½”, the correct answer is:
Most common real meaning:
- ½ (one-half symbol)
Why it happens:
When text like “½” is not decoded correctly, it turns into something like:
- ï ½
- ½
- ½
In short:
| Broken Text | Actual Meaning |
| ï ½ | ½ (half symbol) |
| ½ | ½ |
| – | – (dash) |
Ï ½ï ½ ï ½ï ½ï ½ï ½ï ½ï ½ ï ½ nn ï ½ ï ½ nn ï ½ ï ½ï ½ ï ½ñž ï ½ï ½ï ½ ï
This kind of text is called:
“mojibake” (garbled text caused by encoding mismatch)
What is happening here?
This string is completely broken because:
- Data was encoded in UTF-8
- But read as Latin-1 or Windows-1252
- Or copied through a system that changed encoding
Result:
- Letters become symbols
- Spaces disappear or shift
- Random characters appear like ñ, ï, ½
Important point:
This is NOT a language. It is just corrupted data.
Ï 1 ⁄ 2 decode
The string “Ï 1 ⁄ 2” is another encoding failure.
What it usually means:
It is trying to represent:
½ (one-half symbol)
Why “1 ⁄ 2” appears:
Some systems represent fractions using:
- Unicode fraction slash (⁄)
- Combined characters
But when encoding fails:
- “½” → “Ï 1 ⁄ 2”
Real meaning:
✔ 1/2
✔ half
✔ 0.5
Ï 1 ⁄ 2 decode C#
In C# programming, this issue usually happens when:
- File encoding is wrong
- API response is misread
- Database uses different encoding
Common cause:
Reading UTF-8 text as ANSI or ASCII.
Fix concept (simple explanation):
In C#, the solution is:
- Always ensure UTF-8 encoding is used when reading text
- Match encoding between database, API, and application
Example scenarios:
- Web API returns “½”
- C# reads it incorrectly → “Ï 1 ⁄ 2”
Correct output should be:
✔ ½ (half symbol)
Ï 1 ⁄ 2 decode Python
In Python, this issue is also common when:
- Reading files without specifying encoding
- Handling web scraping data
- Processing CSV or JSON from different sources
Why it happens:
Python may assume wrong encoding like:
- Latin-1
- ASCII
instead of: - UTF-8
Result:
- “½” becomes “Ï 1 ⁄ 2”
- Text becomes unreadable
Fix concept:
- Always ensure correct encoding is used when reading or writing files
- UTF-8 is the safest standard
Ï 1 ⁄ 2 encoding
Now let’s understand the root cause: encoding
What is encoding?
Encoding is a system that tells computers how to convert:
- Letters → numbers
- Numbers → readable text
Common encodings:
| Encoding | Usage |
| UTF-8 | Modern standard |
| ASCII | Basic English characters |
| ISO-8859-1 | Older Western text |
| Windows-1252 | Legacy Windows systems |
Why “ï ½” appears:
It usually happens when:
- UTF-8 text is read as ISO-8859-1
- Or binary data is interpreted incorrectly
Example:
Correct:
- “½” (UTF-8)
Wrong interpretation:
- “ï ½”
Ï ½øªø¹ø ÙÙØ Ø ÙÙ ÙŠ Ù ÙŠ Ø ÙØ ØÙŠÙ ï ½
This long string is a classic encoding disaster.
What it shows:
- Multiple encoding mismatches stacked together
- Likely mix of Arabic, Latin, and Unicode text
Why it happens:
- Copying text between systems with different language support
- Database mismatch (UTF-8 vs non-UTF-8)
- Wrong browser decoding
Result:
- Completely unreadable text
- Mixed symbols and broken characters
Key takeaway:
This is not meaningful text — only encoding corruption.
How to prevent these issues (important section)
To avoid seeing “ï ½” or similar errors:
Always use UTF-8
- It supports almost all languages
- Modern standard for web and apps
Match encoding everywhere
- Database
- API
- Frontend
- Backend
Avoid manual copying between systems
- Especially from Word, PDFs, or old software
Check file encoding before reading
- Most errors happen during file input/output
Why this problem is so common
This issue appears often because:
- Different systems use different encodings
- Internet data comes from many countries
- Old software still uses legacy formats
- Developers forget encoding settings
Quick summary
- “ï ½” is NOT a real symbol
- It usually means “½” (half symbol)
- It happens due to encoding mismatch
- UTF-8 is the correct modern solution
- C# and Python can both produce it if encoding is wrong
FAQs (Frequently Asked Questions)
What does ï 1 ⁄ 2 mean?
It is a broken encoding of the fraction ½, meaning one-half or 0.5.
What is the symbol for 1/2?
The symbol is ½.
Why does ï ½ appear instead of text?
It appears due to encoding mismatch between UTF-8 and older encodings like Latin-1.
Is ï ½ a real character?
No, it is not a real character. It is corrupted text.
How do I fix ï ½ in text?
Fix it by using UTF-8 encoding consistently across systems.
Why does Python show ï 1 ⁄ 2?
Because Python is reading text with the wrong encoding format.
Why does C# show encoding errors like this?
Because the file or API response is not decoded using UTF-8.
Is this a virus or error?
No, it is not a virus. It is only a text encoding issue.
Can this happen in websites?
Yes, if the website does not properly set UTF-8 encoding.
How do developers avoid this issue?
By always standardizing UTF-8 across all systems and databases.
Conclusion
Symbols like “ï ½” or “ï 1⁄2” are not real characters with meaning but the result of text encoding mismatches. They usually occur when data written in UTF-8 is incorrectly read using older encodings such as ISO-8859-1 or Windows-1252. This leads to corrupted or unreadable text known as mojibake. Understanding encoding is essential for developers and users working with text across different systems, especially in Python, C#, and web applications. By consistently using UTF-8 and properly handling file, API, and database encoding, these issues can be easily avoided. Ultimately, correct encoding ensures clean, readable, and reliable digital communication everywhere.
